常用代码片段 示例:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 全局异常处理
*/
@RestControllerAdvice
public class GlobalExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
@ExceptionHandler(value = Exception.class)
public Result<Object> exceptionHandler(Exception e) {
logger.error(e.getMessage(), e);
ErrorEnum serverError = ErrorEnum.INTERNAL_SERVER_ERROR;
return Result.error(serverError.getErrorCode(), serverError.getErrorMsg(), null);
}
}
一、打日志的正确方式
使用slf4j
使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
实现方式统一使用:Logback框架
什么时候应该打日志?
- 当你遇到问题的时候,只能通过debug功能来确定问题,你应该考虑打日志,良好的系统,是可以通过日志进行问题定为的。
- 当你碰到if…else 或者 switch这样的分支时,要在分支的首行打印日志,用来确定进入了哪个分支
- 经常以功能为核心进行开发,你应该在提交代码前,可以确定通过日志可以看到整个流程
- fatal - 严重的,造成服务中断的错误;
- error - 其他错误运行期错误;
- warn - 警告信息,如程序调用了一个即将作废的接口,接口的不当使用,运行状态不是期望的但仍可继续处理等;
- info - 有意义的事件信息,如程序启动,关闭事件,收到请求事件等;
- debug - 调试信息,可记录详细的业务处理到哪一步了,以及当前的变量状态;
- trace - 更详细的跟踪信息;

基本格式
必须使用参数化信息的方式:
logger.debug("Processing trade with id:[{}] and symbol : [{}] ", id, symbol);
对于debug日志,必须判断是否为debug级别后,才进行使用:
if (logger.isDebugEnabled()) {
logger.debug("Processing trade with id: " + id + " symbol: " + symbol);
}
不要进行字符串拼接,那样会产生很多String对象,占用空间,影响性能。
反例(不要这么做):
logger.debug("Processing trade with id: " + id + " symbol: " + symbol);
使用[]进行参数变量隔离
如有参数变量,应该写成如下写法:
logger.debug("Processing trade with id:[{}] and symbol : [{}] ", id, symbol);
这样的格式写法,可读性更好,对于排查问题更有帮助。
二、不同级别的使用
ERROR
基本概念
影响到程序正常运行、当前请求正常运行的异常情况:
- 打开配置文件失败
- 所有第三方对接的异常(包括第三方返回错误码)
- 所有影响功能使用的异常,包括:SQLException和除了业务异常之外的所有异常(RuntimeException和Exception)
不应该出现的情况:
比如要使用Azure传图片,但是Azure未响应
如果有Throwable信息,需要记录完成的堆栈信息:
log.error("获取用户[{}]的用户信息时出错", userName, e);
说明
如果进行了抛出异常操作,请不要记录error日志,由最终处理方进行处理:
反例(不要这么做):
try {
//....
} catch (Exception ex) {
String errorMessage = String.format("Error while reading information of user [%s]", userName);
logger.error(errorMessage, ex);
throw new UserServiceException(errorMessage, ex);
}
WARN
基本概念
不应该出现但是不影响程序、当前请求正常运行的异常情况:
- 有容错机制的时候出现的错误情况
- 找不到配置文件,但是系统能自动创建配置文件
- 即将接近临界值的时候,例如:缓存池占用达到警告线
- 业务异常的记录,比如:当接口抛出业务异常时,应该记录此异常
INFO
基本概念
系统运行信息
- Service方法中对于系统/业务状态的变更
- 主要逻辑中的分步骤
外部接口部分
- 客户端请求参数(REST/WS)
- 调用第三方时的调用参数和调用结果
说明
1.并不是所有的service都进行出入口打点记录,单一、简单service是没有意义的(job除外,job需要记录开始和结束)。
反例(不要这么做):
public List listByBaseType(Integer baseTypeId) {
log.info("开始查询基地");
BaseExample ex = new BaseExample();
BaseExample.Criteria ctr = ex.createCriteria();
ctr.andIsDeleteEqualTo(IsDelete.USE.getValue());
Optionals.doIfPresent(baseTypeId, ctr::andBaseTypeIdEqualTo);
log.info("查询基地结束");
return baseRepository.selectByExample(ex);
}
2.对于复杂的业务逻辑,需要进行日志打点,以及埋点记录,比如电商系统中的下订单逻辑,以及OrderAction操作(业务状态变更);
3.对于整个系统的提供出的接口(REST/WS),使用info记录入参;
4.如果所有的service为SOA架构,那么可以看成是一个外部接口提供方,那么必须记录入参;
5.调用其他第三方服务时,所有的出参和入参是必须要记录的(因为你很难追溯第三方模块发生的问题);
DEBUG
基本概念
- 可以填写所有的想知道的相关信息(但不代表可以随便写,debug信息要有意义,最好有相关参数)
- 生产环境需要关闭DEBUG信息
- 如果在生产情况下需要开启DEBUG,需要使用开关进行管理,不能一直开启。
说明
如果代码中出现以下代码,可以进行优化:
//1. 获取用户基本薪资 //2. 获取用户休假情况 //3. 计算用户应得薪资
优化后的代码:
logger.debug("开始获取员工[{}] [{}]年基本薪资", employee, year);
logger.debug("获取员工[{}] [{}]年的基本薪资为[{}]", employee, year, basicSalary);
logger.debug("开始获取员工[{}] [{}]年[{}]月休假情况", employee, year, month);
logger.debug("员工[{}][{}]年[{}]月年假/病假/事假为[{}]/[{}]/[{}]", employee, year, month, annualLeaveDays, sickLeaveDays, noPayLeaveDays);
logger.debug("开始计算员工[{}][{}]年[{}]月应得薪资", employee, year, month);
logger.debug("员工[{}] [{}]年[{}]月应得薪资为[{}]", employee, year, month, actualSalary);
TRACE
基本概念
特别详细的系统运行完成信息,业务代码中,不要使用。(除非有特殊用意,否则请使用DEBUG级别替代)
规范示例说明
@Override
@Transactional
public void createUserAndBindMobile(@NotBlank String mobile, @NotNull User user) throws CreateConflictException {
boolean debug = log.isDebugEnabled();
if (debug) {
log.debug("开始创建用户并绑定手机号 . args[mobile=[{}],user=[{}]]", mobile, LogObjects.toString(user));
}
try {
user.setCreateTime(new Date());
user.setUpdateTime(new Date());
userRepository.insertSelective(user);
if (debug) {
log.debug("创建用户信息成功. insertedUser=[{}]", LogObjects.toString(user));
}
UserMobileRelationship relationship = new UserMobileRelationship();
relationship.setMobile(mobile);
relationship.setOpenId(user.getOpenId());
relationship.setCreateTime(new Date());
relationship.setUpdateTime(new Date());
userMobileRelationshipRepository.insertOnDuplicateKey(relationship);
if (debug) {
log.debug("绑定手机成功. relationship=[{}]", LogObjects.toString(relationship));
}
log.info("创建用户并绑定手机号. userId=[{}],openId=[{}],mobile=[{}]", user.getId(), user.getOpenId(), mobile);
} catch(DuplicateKeyException e) {
log.info("创建用户并绑定手机号失败,已存在相同的用户. openId=[{}],mobile=[{}]", user.getOpenId(), mobile);
throw new CreateConflictException("创建用户发生冲突, openid=[%s]", user.getOpenId());
}
}
三、基本的Logger编码规范
1.在一个对象中通常只使用一个Logger对象,Logger应该是static final的,只有在少数需要在构造函数中传递logger的情况下才使用private final。
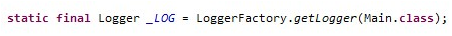
2.输出Exceptions的全部Throwable信息,因为logger.error(msg)和logger.error(msg,e.getMessage())这样的日志输出方法会丢失掉最重要的StackTrace信息。
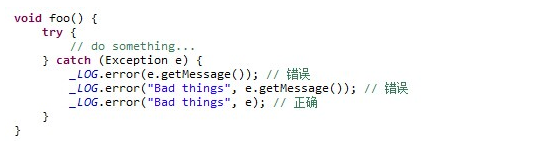
3.不允许记录日志后又抛出异常,因为这样会多次记录日志,只允许记录一次日志。

4.不允许出现System print(包括System.out.println和System.error.println)语句。
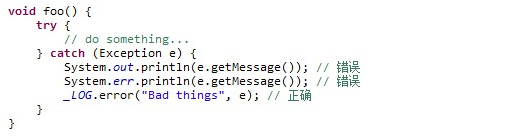
5.不允许出现printStackTrace。

6.日志性能的考虑,如果代码为核心代码,执行频率非常高,则输出日志建议增加判断,尤其是低级别的输出<debug、info、warn>。
debug日志太多后可能会影响性能,有一种改进方法是:

但更好的方法是Slf4j提供的最佳实践:

一方面可以减少参数构造的开销,另一方面也不用多写两行代码。
7.有意义的日志
通常情况下在程序日志里记录一些比较有意义的状态数据:程序启动,退出的时间点;程序运行消耗时间;耗时程序的执行进度;重要变量的状态变化。
初次之外,在公共的日志里规避打印程序的调试或者提示信息。
参考:
- https://www.imooc.com/article/255860
- https://www.jb51.net/article/164159.htm
- https://www.cnblogs.com/coding-night/p/10748708.html
- [荐]https://zhuanlan.zhihu.com/p/109237510
某网友的经验:
简单的说,就是配合log的等级过滤输出
比如,你在开发的时候,要验证一个方法有没有被调用到,为了方便调试,通常会在这个方法开始的时候加一些system.out。但是项目真正发布的时候这些代码通常是要移除掉的,所以通常更建议用logger来记录。
你可能会加logger.debug。 为什么是debug而不是info、error或者其他呢?因为通常项目发布的时候都会把日志等级设置为error 或者info之类的等级,在这两个等级下,debug的内容是输出不了的,所以就可以做到不需要修改代码就不会输出你只有在调试的时候才需要输出的内容。
各个等级都是有它的含义的,虽然在代码写的时候你用debug、info、error都是可以,但是为了方便管理,只有调试的时候才用到日志会用debug,一些信息类的日志记录通常会用info(比如你想看一天有几个用户登录),一些错误的,或者异常信息会用error,比如某个时刻数据库连接出了问题,如果分析日志,直接搜索error开头的就能直接定位到了。