Python收藏 | Pandas收藏 | Java爬虫 | Python爬虫 | 【爬虫】相关资源(代理) | PyWinAuto收藏
MitmProxy中文文档 、Scrapy爬虫框架 、Selenium 之chromedriver下载
==》 把chromedriver路径设置到系统环境变量下即可使用
设置代理、自定义头信息
pip install selenium pip install selenium-wire
- 用Selenium给chrome添加任意请求头信息
- Selenium&Selenium-wire使用
- python使用Selenium以及Selenium-wire做质量与性能检测
- Python Selenium 4 新版本使用指南
- Selenium.get() 等待与超时
Selenium反爬设置
Selenium
- [上海-悠悠]Selenium专题
- 使用无头(headless)浏览器帮你节省自动化运行时间
- 【Selenium】find_element_by_css_selector()使用示例
- 【Selenium】WebElement元素(DOM元素)的 属性 和 方法
- 【Selenium】获取某个元素的Html之.get_attribute('outerHTML')
- 【Selenium】利用select模块处理下拉框(Select/Options)
- 【Selenium】设置等等时间
- 【Selenium】<显性等待> Ajax加载完成后
- 【Selenium】关闭提示:Chrome 正受到自动测试软件的控制
- 【Selenium】定位:出现Message: element not interactable 元素不可交互的问题解决方案
- 【Selenium】报错 ERROR:ssl_client_socket_impl.cc(962)] handshake failed;returned -1, SSL error code 1
经验分享:
捕获异常时,统一使用如下异常类型(Exception)代码:使用具体化的异常类(如:TimeoutException)的话,容易漏写其他类型的异常,导致程序中断
try:
element_page_list = WebDriverWait(driver, Loading_Timeout_10sec).until(
ec.presence_of_all_elements_located((By.CSS_SELECTOR, ".s-pagination-container .s-pagination-strip span"))
)
except Exception as e:
logger_exception("没有查询到【分页记录】")
页面跳转(多窗口):
- 【Selenium】如何点击<a>标签直接跳转网页
- 在Selenium中window.open()和click()点击链接的区别(新窗口打开链接)
- 【Selenium】点击链接进入子页面抓取内容(新闻抓取案例一)
- 【Selenium】点击链接进入子页面抓取内容(新闻抓取案例二)
- 【Selenium】多窗口切换、句柄(handle)
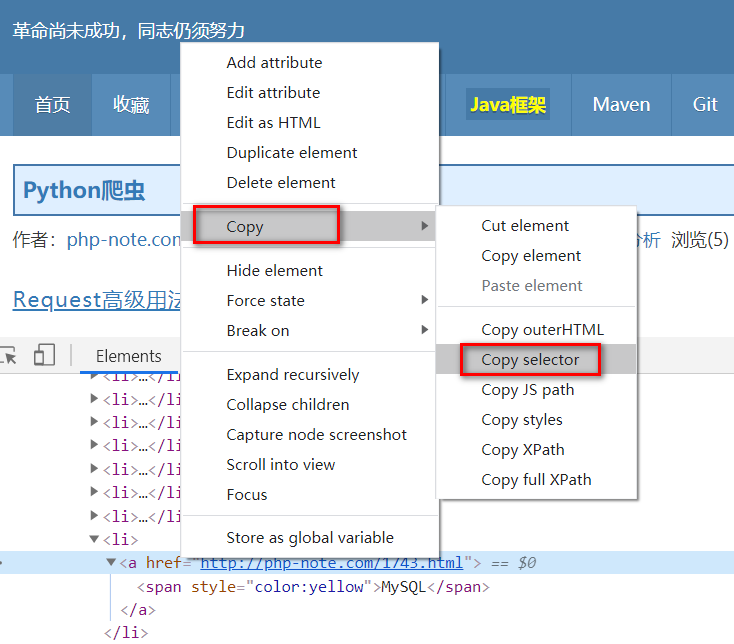
find_element_by_css_selector()
浏览器获取CSS选择器技巧:元素选择器 -> 右键HTML元素节点 -> Copy -> Copy Selector
- Python爬虫 - Selenium(1)安装和简单使用 详细介绍Selenium的依赖环境在Windows和Centos7上的安装及简单使用
- Python爬虫 - Selenium(2)元素定位和WebDriver常用方法 详细介绍定位元素的8种方式并配合点击和输入、提交、获取断言信息等方法的使用
- Python爬虫 - Selenium(3)控制浏览器的常用方法 详细介绍自定义浏览器窗口大小或全屏、控制浏览器后退、前进、刷新浏览器等方法的使用
- Python爬虫 - Selenium(4)配置启动项参数 详细介绍Selenium启动项参数的配置,其中包括无界面模式、浏览器窗口大小设置、浏览器User-Agent (请求头)等等
- Python爬虫 - Selenium(5)鼠标事件 详细介绍鼠标右击、双击、拖动、鼠标悬停等方法的使用
- Python爬虫 - Selenium(6)键盘事件 详细介绍键盘的操作,几乎包含所有常用按键以及组合键
- Python爬虫 - Selenium(7)多窗口切换 详细介绍Selenium是如何实现在不同的窗口之间自由切换
- Python爬虫 - Selenium(8)frame/iframe表单嵌套页面 详细介绍如何从当前定位的主体切换为frame/iframe表单的内嵌页面中
- Python爬虫 - Selenium(9)警告框(弹窗)处理 详细介绍如何定位并处理多类警告弹窗
- Python爬虫 - Selenium(10)下拉框处理 详细介绍如何灵活的定位并处理下拉框
- Python爬虫 - Selenium(11)文件上传 详细介绍如何优雅的通过send_keys()指定文件进行上传
- Python爬虫 - Selenium(12)获取登录Cookies,并添加Cookies自动登录 详细介绍如何获取Cookies和使用Cookies进行自动登录
- Python爬虫 - Selenium(13)设置元素等待 详细介绍如何优雅的设置元素等待时间,防止程序运行过快而导致元素定位失败
- Python爬虫 - Selenium(14)窗口截图 详细介绍如何使用窗口截图
- Python爬虫 - Selenium(15)关闭浏览器 详细介绍两种关闭窗口的区别