工作实践
【备份】
/www/server/pgsql/bin/pg_dump -h pgm-wz945tn6vg730xxx.pg.rds.aliyuncs.com -U postgres -d db_informat_biz_prd_0 -f /alidata/tmp/db_informat_biz_prd_0.sql /www/server/pgsql/bin/pg_dump -h pgm-wz945tn6vg730xxx.pg.rds.aliyuncs.com -U postgres -d db_informat_account_prd -f /alidata/tmp/db_informat_account_prd.sql
【还原】
/www/server/pgsql/bin/psql -h pgm-wz94c8089nj67xxx.pg.rds.aliyuncs.com -U postgres -d db_informat_biz_prd_0 -f /alidata/tmp/db_informat_biz_prd_0.sql /www/server/pgsql/bin/psql -h pgm-wz94c8089nj67xxx.pg.rds.aliyuncs.com -U postgres -d db_informat_account_prd -f /alidata/tmp/db_informat_account_prd.sql
一、逻辑备份
1.pg_dump工具
以下为pg_dump工具的常用参数选项(更多参数可使用pg_dump --help查看)
联接选项: -h, --host=主机名 数据库服务器的主机名或套接字目录 -U, --username=名字 以指定的数据库用户联接 -d, --dbname=DBNAME 对数据库 DBNAME备份 -p, --port=端口号 数据库服务器的端口号 -w, --no-password 永远不提示输入口令 -W, --password 强制口令提示 (自动) --role=ROLENAME 在转储前运行SET ROLE 一般选项: -f, --file=FILENAME 输出文件或目录名,导出到指定文件 -F, --format= p|c|d|t 导出文件格式(p|c|d|t) p:plain-输出普通文字SQL脚本(默认); c:custom-输出自定义归档格式,适用于pg_restore导入,该格式是最灵活导出方式,允许在导入时自定义选择和重 排序归档条目。该格式默认启用压缩; d:directory-输出文件夹归档格式,适用于pg_restore导入。该格式会创建一个文件夹,一个表对应一个文件。该格式默认启用压缩,并且支持并行导出; t:tar-输出tar压缩归档格式,适用于pg_restore导入。该格式将文件夹归档格式产生的文件夹压缩成tar压缩包。但该格式不支持压缩(文件夹归档已经压缩了),并且在导入时也不能更改相关的表顺序。 控制输出内容选项: -s, --schema-only 只转储模式, 不包括数据 -a, --data-only 只转储数据,不包括模式 -t, --table=TABLE 只转储指定名称的表 -T, --exclude-table=TABLE 不转储指定名称的表 -C, --create 在转储中包括创建数据库语句 -c, --clean:包含drop删除语句,建议与--if-exists同时使用; --if-exists,drop删除语句时带上IF EXISTS指令 -n, --schema=SCHEMA 只转储指定名称的模式 -N, --exclude-schema=SCHEMA 不转储已命名的模式 -O, --no-owner 在明文格式中, 忽略恢复对象所属者 -S, --superuser=NAME 在明文格式中使用指定的超级用户名 --column-inserts 以带有列名的INSERT命令形式转储数据 --inserts 以INSERT命令,而不是COPY命令的形式转储数据 --disable-triggers 在只恢复数据的过程中禁用触发器 --exclude-table-data=TABLE 不转储指定名称的表中的数据 --no-synchronized-snapshots 在并行工作集中不使用同步快照 --no-tablespaces 不转储表空间分配信息 --no-unlogged-table-data 不转储没有日志的表数据 --quote-all-identifiers 所有标识符加引号,即使不是关键字 --section=SECTION 备份命名的节 (数据前, 数据, 及 数据后) --serializable-deferrable 等到备份可以无异常运行 --snapshot=SNAPSHOT 为转储使用给定的快照 --strict-names 要求每个表和/或schema包括模式以匹配至少一个实体
常用示例:
#备份schema及数据,指定数据库pg_hive,指定文件为pg_hive20210108.sql pg_dump -h 127.0.0.1 -U postgres -d pg_hive -f /opt/pg_hive20210108.sql #只备份schema pg_dump -h 127.0.0.1 -U postgres -d pg_hive -s -f /opt/pg_hive20210108.sql #只备份数据 pg_dump -h 127.0.0.1 -U postgres -d pg_hive -a -f /opt/pg_hive20210108.sql #备份单个表 pg_dump -h 127.0.0.1 -U postgres -d pg_hive –t table1 -f /opt/pg_hive20210108.sql #备份多个表 pg_dump -h 127.0.0.1 -U postgres -d pg_hive –t table1 –t table2 -f /opt/pg_hive20210108.sql #以带有列名的INSERT命令形式转储数据 pg_dump -h 127.0.0.1 -U postgres -d pg_hive --column-inserts -f /opt/pg_hive20210108.sql #指定导出格式为自定义格式(二进制形式) pg_dump -h 127.0.0.1 -U postgres -d pg_hive -Fc -f /opt/pg_hive20210108.dump #使用gzip压缩转储(针对大型数据库) pg_dump -h 127.0.0.1 -U postgres -d pg_hive | gzip > /opt/pg_hive20210108_gz.sql.gz #使用split切片文件(针对大型数据库) /pg_dump -h 127.0.0.1 -U postgres -d pg_hive | split -b 100m - /opt/pg_hive20210108_sp.sql
2.pg_dumpall工具
相对于pg_dump只能备份单个库,pg_dumpall可以备份整个PostgreSql实例中所有的数据,包括角色和表空间定义。
使用示例:
#备份整个postgresql实例中所有的数 pg_dumpall -h 127.0.0.1 -U postgres -f /opt/pg_hive20210108_all.sql
二、逻辑备份还原
逻辑备份的还原命令为psql和pg_restore:
如果使用pg_dump未指定format(即未使用-F参数),则导出的是SQL脚本,导入时需用psql命令,否则用pg_restore还原。因这2个还原工具大部分参数与pg_dump含义相近,可使用命令后加–help查看详细参数。
常用示例:
#pg_dump备份时未指定format,还原时用psql psql -h 127.0.0.1 -U postgres -d pg_hive -f /opt/pg_hive20210108.sql #pg_dump备份时候使用-F参数指定format,还原时用pg_restore pg_restore -h 127.0.0.1 -U postgres -d pg_hive /opt/pg_hive20210108.dump #还原gzip压缩数据库备份 gunzip -c /opt/pg_hive20210108_gz.sql.gz | psql -h 127.0.0.1 -U postgres -d pg_hive #还原切片数据库备份 cat /opt/pg_hive20210108_sp.sql* | psql -h 127.0.0.1 -U postgres -d pg_hive
三、连续归档备份
连续归档是通过基础备份和wal日志相结合的方式进行备份,恢复的时候可以选择恢复到指定的时间点、指定事务点、或者完全恢复到wal日志的最新位置。
操作步骤如下:
1、创建备份目录
#创建基础备份目录 mkdir -p /data/pg_base #创建wal日志备份目录 mkdir -p /data/pg_archive
2、修改配置文件
打开postgresql.conf配置文件,修改以下3个参数:
vi postgresql.conf #wal_level中有三个主要的参数:minimal、archive和hot_standby。1.minimal是默认的值,它仅写入崩溃或者突发关机时所需要的信息(不建议使用)。2.archive是增加wal归档所需的日志(最常用)。3.hot_standby是在备用服务器上增加了运行只读查询所需的信息,一般实在流复制的时候使用到 wal_level = archive #开启归档模式 archive_mode = on #备份wal日志,每天生成一个日期命名的文件夹 archive_command = 'DIR=/data/pg_archive/`date +%F`; test ! -d $DIR && mkdir -p $DIR; test ! -f $DIR/%f && cp %p $DIR/%f'
3、重启pg数据库
命令为:pg_ctl restart
4、创建表
该步骤为测试备份及恢复效果使用
--创建表,插入10条测试数据: create table test (id integer); insert into test values(generate_series(1,10));
5、做基础备份
pg_basebackup -Ft -Pv -Xf -z -Z5 -D /data/pg_base/`date +%F`
为了测试备份和恢复效果,再插入10条数据,并进行手动切换wal日志,执行如下sql:
#插入数据 insert into test values(generate_series(1,10)); #切换wal日志 select pg_switch_wal();
四、连续归档恢复
1、创建data文件夹
#重命名原来的data文件夹 mv /pgsql/postgresql/data /pgsql/postgresql/data.bak #创建新的data文件夹 mkdir data
2、解压基础备份至新建的data文件夹
#拷贝基础备份到新建data文件夹 cp /data/pg_base/2021-01-15/base.tar.gz /pgsql/postgresql/data #解压文件 tar -zxvf base.tar.gz #删除基础备份中的wal日志和postmaster.pid文件 Cd /pgsql/postgresql/data rm -rf pg_wal rm -rf postmaster.pid #创建archive_status文件夹 mkdir -p pg_wal/archive_status
3、修改配置文件
vi postgresql.conf #修改restore_command为要恢复的wal日志目录 restore_command = 'cp /data/pg_archive/2021-01-15/%f %p'
4、新建recovery.signal文件
#恢复时依赖该文件,恢复至最新wal位置,文件无需添加内容 touch recovery.signal
5、赋权并启动数据库
#新建的data文件夹更改所有者 chown -R postgres:postgres /pgsql/postgresql/data #修改data目录权限,否则会因为目录权限过大无法启动数据库 chmod 0700 data -R #启动数据库 pg_ctl start
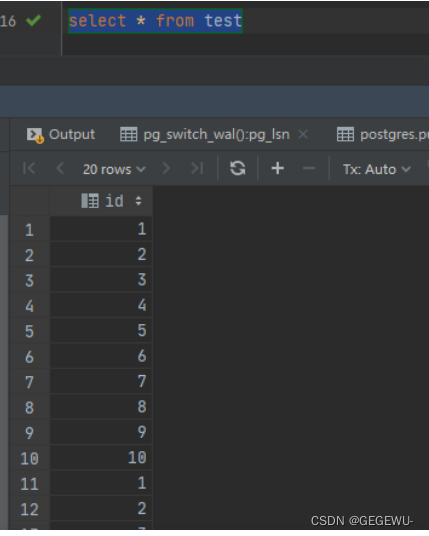
6、验证恢复效果
如下图,已通过基础备份和wal日志恢复全部数据
相关文章:
[阿里云] 使用pg_dump和pg_restore将自建PostgreSQL数据库迁移到RDS PostgreSQL