之前写了一篇 Go 方法接收者(指针 vs. 值) 的文章,解决了定义方法(本质是函数传参)的类型选择问题。现在,我们来探讨一下另一个常见问题:
当你在 struct 中定义字段时,到底该用 Entry(值)、*Entry(指针)、[]Entry(值切片)还是 []*Entry(指针切片)?
type Entry struct {
Name string
Value int32
}
type MyStruct struct {
data1 Entry
data2 *Entry
data3 []Entry
data4 []*Entry
}
这是一个比“方法接收者”更复杂的决策。如果说“方法接收者”是一个单一的权衡(修改 vs. 复制),那么“结构体字段”就是多个权衡的复杂组合,比如说:内存布局是连续的还是离散的?程序语义是什么?性能怎么样?GC 压力大吗?等等...
但好消息是,我们可以将这些所有的问题,全都归纳总结为以下三个具体的问题:
-
程序语义: 这个字段需要“空”( nil)的含义吗? -
代码性能: 你需要“连续”的内存或者避免大拷贝吗? -
并发安全: 这个数据是被“拥有”还是被“共享”?
我们接下来详细说说。
如何决策
问题一:这个字段需要“空”(nil)的含义吗?
这是最简单、也最常见的决策点。
在业务逻辑中,“空”或“未设置”是一种非常重要的状态。我们先来看前两个字段:
-
data1 Entry(值):它永远不可能为nil。它的“零值”是Entry{},一个空的Entry不是nil。 -
data2 *Entry(指针):它的“零值” 就是nil。
如果你的字段在数据库中是 NULLABLE,或者你的业务逻辑需要在 JSON 中区分 {"entry": {}} 和 {"entry": null}(或根本没有 entry 键),那么你必须使用指针(*T)。
场景:
data2 *Entry是可选配置,nil意味着“使用系统默认值”。data1 Entry是必填项,它总得有一个值(哪怕是Entry{})。同样,
data4 []*Entry允许列表中的某个元素为nil,而data3 []Entry则不行。
问题二:性能(复制成本 vs. 缓存友好)
内存布局(连续 vs. 离散)是决定程序性能的核心。性能考量主要分为两种场景:
场景一:单个对象的复制成本(T vs. *T)
对于 data1 这样的内嵌值,它在访问速度和 GC 压力上通常优于data2(指针),因为它避免了指针解引用和额外的堆分配。
然而,这条规则有一个重要例外:如果 Entry 结构体本身极其巨大(例如,它内部包含一个大数组或几百个字段),情况就反过来了。此时,data1 Entry(值)会导致 MyStruct 在被复制时(s2 := s1),产生极高昂的“深复制”成本。
在这种情况下,即使你不需要 nil 语义,也可能被迫使用 data2 *Entry(指针),来确保 MyStruct 本身可以被廉价地复制(只复制一个 8 字节的指针)。
场景二:集合的迭代性能([]T vs. []*T)
这是性能考量的另一个极端:data3 []Entry vs. data4 []*Entry。
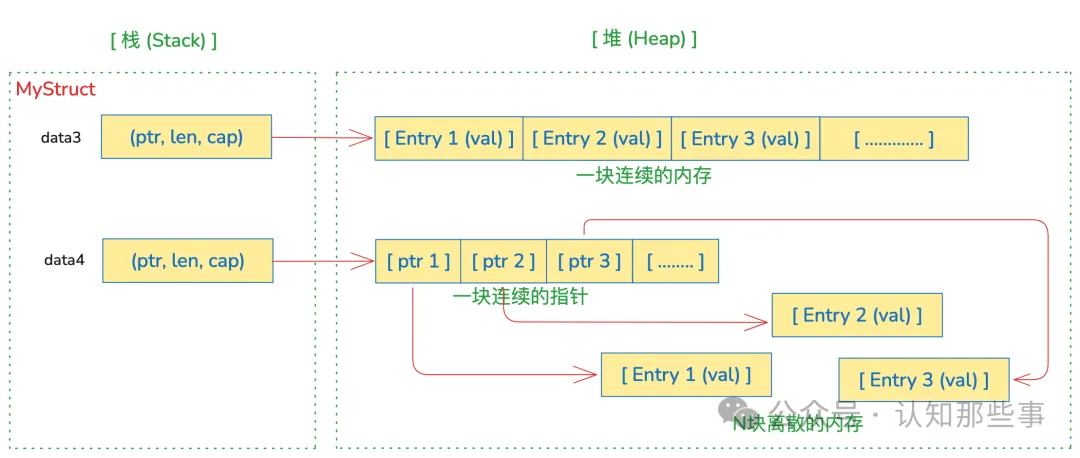
我们先看图片,直观的感受一下它们的内存布局:
Go 结构体内存布局
首先,值切片(data3 []Entry)在 MyStruct 内部存放的是一个切片头(指针、len、cap),其指针指向“堆”上一块连续的内存([Entry1][Entry2][Entry3][...])。
对于“连续”的内存布局,迭代它时,由于数据在内存中是紧挨着的,CPU 就可以利用“缓存局部性”(Cache Locality),提前把 Entry2、Entry3 加载到高速缓存中。结果就是迭代速度极快。
我们再来看指针切片(data4 []*Entry)。它在 MyStruct 内部的切片头指向的是“堆”上一块连续的指针([Ptr1][Ptr2][Ptr3][...]),这些指针又各自指向堆上不同位置的 Entry 数据。这样的数据结构会如何迭代呢?大概是这样:
-
CPU 访问 data4[i],从内存中取出Ptr_i。 -
CPU 必须再次访问内存,通过 Ptr_i找到Entry_i的数据。 -
这个 Entry_i数据可能在内存的任何角落,导致“缓存未命中”(Cache Miss)。
如此来看,data4 切片中的每一个元素,都需要两次内存访问,并且离散的数据分布根本无法利用 CPU 高速缓存,迭代它就是一场性能灾难。
那么,GC 的压力怎么样呢?
我们假设切片中有 1000 个元素。在 data3 这种连续的内存布局中,这 1000 个元素是 1 个大对象(即底层数组),GC 只需要跟踪这一个对象(那块连续的内存)。而 data4 是 1001 个离散的小对象,GC 需要跟踪 1001 个对象(即 1 个(指针)数组 + 1000 个 T 对象)。这会显著增加 GC 的扫描和标记时间。
因此,在性能这个维度上,“值”类型(data1 Entry 和 data3 []Entry)完胜。除非 Entry 本身大到无法接受复制。
问题三:这个数据是被“拥有”还是被“共享”?
这是最微妙的一个问题,它关乎“程序语义”和“并发安全”。
所谓的“拥有”的含义,就是指 data1 Entry 这样的“值”类型的字段,这个字段的 Entry 数据被“内嵌”在 MyStruct 结构体内部,data1 的数据是 MyStruct “肉体” 的一部分。所以说 MyStruct 完全拥有data1。
当你复制 MyStruct(s2 := s1) 时,这种“拥有”的性质会让 data1 被深度复制。此时,s2.data1 和 s1.data1 是两个独立的东西。这在并发时是(默认)安全的。
那什么是 “共享” 呢?
同样地,你刚刚的复制行为对于 data2 来说,效果完全不同。因为这是指针的复制,所以,s2.data2 和 s1.data2 指向同一个Entry 对象。因此,这两个 MyStruct 共享data2。
对于 data3 []Entry 和 data4 []*Entry 两个切片来说,它们都是引用类型,当进行 s2 := s1 这样的简单复制场景,是一个浅复制的操作。因此,s1 和 s2共享了底层数组。
由此可见,data1(值)是这四种中唯一在复制时进行“深复制”的。data2(指针)、data3(值切片)和 data4(指针切片)在 s2 := s1 复制时,全都是浅复制。
这种“浅复制”带来的“共享”性质,其主要风险在于并发不安全。比如说:一个 goroutine 通过 s1.data2 修改 Name,另一个 goroutine 通过 s2.data2 修改 Name,这就会发生数据竞争(Data Race)。同样地,两个 goroutine 同时修改 data3[0].Name 或 data4[0].Name 也都会发生数据竞争。
那么,既然 data2、data3、data4 都是“共享”且有并发风险,为什么我们还要区分它们?
区别在于“共享”的效率和意图:
-
data1 T:真正的“拥有”。默认并发安全。 -
data2 *T:有意 “共享” 单个对象。 -
data3 []T:“共享” 1 个大对象(底层数组)。GC 效率很高。 -
data4 []*T:“共享” N+1 个离散对象(切片本身 + N个元素)。GC 效率最低。
综上所述,在“拥有 vs. 共享”这个维度上,做决策时,你需要问自己:
-
我是否需要绝对的并发安全和“拥有”语义? -> 如果是,则选择 data1 T。 -
我是否需要共享数据?如果是,则有两种情况: -
愿意承受 N+1 的 GC 压力 -> 选择 data4 []*T。 -
只想高效地(在 GC 层面)共享一个列表 -> 选择 data3 []T。
-
如何解决并发风险?
你可以为 MyStruct 实现一个
deepcopy方法,其唯一目的就是消除所有共享,创建出一个 100% 独立的“克隆体”。那么s1和s2 := s1.DeepCopy()之间就没有任何共享了,此时,data1、data2、data3和data4全都是并发安全的。
总结
总结一下,本文的主要内容可以简化为两条黄金法则:
-
单个对象(
Tvs*T): 首选使用T(值),它更快、更安全(并发)、GC 压力更小。只有当你需要可选性(nil)、避免大拷贝或有意共享时,才使用*T(指针)。 -
集合(
[]Tvs[]*T): 首选使用[]T(值切片),它在内存、迭代性能和 GC 上的优势是碾压性的。只有当你需要元素为nil或元素被共享(且你愿意承受 N+1 的 GC 压力)时,才被迫使用[]*T(指针切片)。
我们本文讨论了 T,*T,[]T,[]*T 四种不同类型的结构体字段如何选择,并给出了清晰的决策思路。虽然例子用的是Entry和切片类型,但你可以轻松的推广到所有的值类型和引用类型(如 map[string]T,chan T 等),它们背后的原理都是通用的。