简单来讲,Selector会不断地轮询注册在其上的Channel,如果某个Channel上面有新的TCP连接接入、读和写事件,这个Channel就处于就绪状态,会被Selector轮询出来,然后通过SelectionKey可以获取就绪Channel的集合,进行后续的I/O操作。
ReplayingDecoder 和ByteToMessageDecoder 最大的不同就是ReplayingDecoder 允许你实现decode()和decodeLast()就像所有的字节已经接收到一样,不需要判断可用的字节,举例,下面的ByteToMessageDecoder 实现:
public class IntegerHeaderFrameDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx,
ByteBuf buf, List<Object> out) throws Exception {
if (buf.readableBytes() < 4) {
return;
}
buf.markReaderIndex();
int length = buf.readInt();
if (buf.readableBytes() < length) {
buf.resetReaderIndex();
return;
}
out.add(buf.readBytes(length));
}
}
首先来看一下List接口中的sort()方法

从这个描述我们可以看到,我们可以根据具体的Comparator对List结合中的元素进行排序,如果传入的comparator是null的时候,那么集合中的元素必须实现Comparable接口实现自然排序。从上面的一段话我们知道List集合对元素排序的方法有以下两种:
- List中的元素自己实现一个Comparable接口实现一个自然排序
- 我们通过传入一个实现了Comparator接口实现一个排序
Java正则表达式:
- (?i)abc 表示abc都忽略大小写
- a(?i)bc 表示bc忽略大小写
- a((?i)b)c 表示只有b忽略大小写
也可以用 Pattern.compile(rexp, Pattern.CASE_INSENSITIVE) 表示整体都忽略大小写
// 高效率访问方式
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
File 类的介绍:/article/.html...
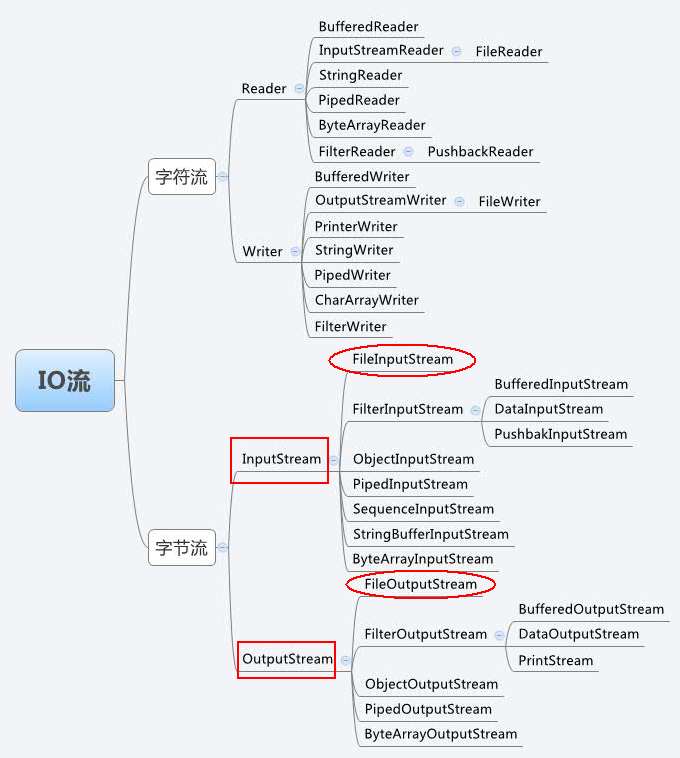
Java IO 流的分类介绍:/article/.html...
这篇讲的是字节输入输出流:InputStream、OutputSteam(下图红色长方形框内),红色椭圆框内是其典型实现(FileInputSteam、FileOutStream)
模拟表单html如下:
<form action="up_result.jsp" method="post" enctype="multipart/form-data" name="form1" id="form1"> <input type="text" name="name" value="" /> <br/> <input type="file" name="userfile" /> <br/> <input type="submit" value="上传" /> </form>