Channel是一个通道,可以通过它读取和写入数据,它就像自来水管一样,网络数据通过Channel读取和写入。通道与流的不同之处在于通道是双向的,流只是在一个方向上移动(一个流必须是InputStream或者OutputStream的子类),而且通道可以用于读、写或者同事用于读写。因为Channel是全双工的,所以它可以比流更好地映射底层操作系统的API。特别是在UNIX网络编程模型中,底层操作系统的通道都是全双工的,同时支持读写操作。
我们在 Java IO 流的分类介绍 这篇博客中介绍知道:
根据功能分为 节点流 和 包装流(处理流)
节点流:可以从或向一个特定的地方(节点)读写数据,如FileReader。
包装流(处理流):是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
sigh,很遗憾,没有写完整,还有很多想做而没有做的事情,总结一下想做而没有做的事情吧
1)性能测试,没有条件和环境给我做这个事情
2)对portal,对页面的支持,没有一个可以直观的可视页面
3)注册中心对zookeeper的支持
4)监控中心链路调用的追踪的支持,这个很重要,不过没有做
- 【有参考价值】Java架构之 项目结构(Entity / DTO / VO)
- 阿里巴巴Java开发手册中的DO、DTO、BO、AO、VO、POJO定义
- Bean、DTO、VO、Entity、Form...?
- [荐]浅析VO、DTO、DO、PO的概念、区别和用处
- [荐]了解JAVA中的POJO,Entity,PO,VO,DTO,DM包括代码举例展示
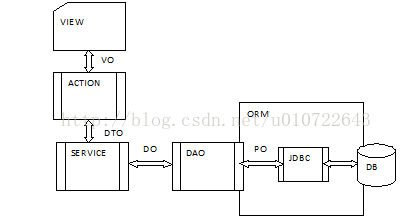
- [荐][图]实体类(VO,DO,DTO,PO)的划分
1、数据库表统一用 utf-8 编码;
2、MyBatis 连接 MySQL 时,指定 utf-8 编码方式,如 mysql.properties 的内容:
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://127.0.0.1:3306/lesjava-blog?useUnicode=true&characterEncoding=utf8 jdbc.username=root jdbc.password=123456
提示:
springframework里面带了一个 获取 md5的方法 DigestUtils.md5DigestAsHex()
Javadoc虽然是Sun公司为Java文档自动生成设计的,可以从程序源代码中抽取类、方法、成员等注释形成一个和源代码配套的API帮助文档。但是Javadoc的注释也符合C的注释格式,而且doxyen也支持该种风格的注释。
官方文档:http://docs.oracle.com/javase/7/docs/technotes/tools/windows/javadoc.html
维基百科:https://en.wikipedia.org/wiki/Javadoc
Javadoc 的注释结构和 C 类似。都以/* 注释 */这种结构。
Set排序
Set包括HashSet和TreeSet,HashSet是基于HashMap的,TreeSet是基于TreeMap的。
TreeMap是用红黑树实现,天然就具有排序功能,“天然就具有排序功能”是指它拥有升序、降序的迭代器。
那么HashSet怎么排序呢?我们可以将HashSet转成List,然后用List进行排序。
一、无依赖其他任何jar
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.think.TestMain</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>