作者:AlbertWen
添加时间:2017-10-26 17:48:14
修改时间:2026-03-22 12:05:05
分类:
13.C/C++/Rust
编辑
一、sprintf() 函数详解
在将各种类 型的数据构造成字符串时,sprintf 的强大功能很少会让你失望。
由于 sprintf 跟 printf 在用法上几乎一样,只是打印的目的地不同而已,前者打印到字符串中,后者则直接在命令行上输出。这也导致 sprintf 比 printf 有用得多。所以本文着重介绍 sprintf,有时也穿插着用用 pritnf。
sprintf是个变参函数,定义如下:
int sprintf( char *buffer, const char *format [, argument] … );
除了前两个参数类型固定外,后面可以接任意多个参数。而它的精华,显然就在第二个参数:格式化字符串上。
作者:AlbertWen
添加时间:2017-10-27 10:28:29
修改时间:2026-03-31 02:14:42
分类:
15.OpenResty_Lua
编辑
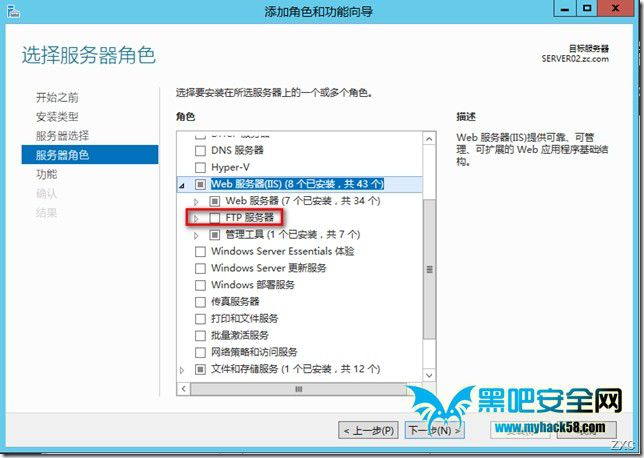
在Server2012打开 服务器管理器,选择 添加角色与功能,添加Web服务下的FTP服务器
作者:AlbertWen
添加时间:2015-03-01 10:18:01
修改时间:2026-04-02 01:14:37
分类:
02.前端/Vue/Node.js
编辑
扩展jQuery插件和方法的作用是非常强大的,它可以节省大量开发时间。这篇文章将概述jQuery插件开发的基本知识,最佳做法和常见的陷阱。
作者:AlbertWen
添加时间:2015-02-28 23:02:28
修改时间:2026-04-02 17:06:55
分类:
02.前端/Vue/Node.js
编辑
一般来说,jQuery插件的开发分为两种:一种是挂在jQuery命名空间下的全局函数,也可称为静态方法;另一种是jQuery对象级别的方法,即挂在jQuery原型下的方法,这样通过选择器获取的jQuery对象实例也能共享该方法。
作者:AlbertWen
添加时间:2018-11-04 20:03:54
修改时间:2026-03-24 00:41:46
分类:
08.Java基础
编辑
所谓负载策略,其实相对比较简单,某个消费者去远程调用某个服务,不过提供这个服务不止一个实例,那么建立的长连接就不止一个,所以需要做的事情就是根据某个策略在这个长连接中选择一个进行通讯
本Demo RPC只实现了三个比较常用的负载策略
1)随机
2)加权随机
3)轮询
作者:AlbertWen
添加时间:2015-02-27 00:01:10
修改时间:2026-03-27 01:20:29
分类:
13.C/C++/Rust
编辑
作者:AlbertWen
添加时间:2015-02-25 20:40:21
修改时间:2026-04-03 05:16:55
分类:
电脑/软件使用
编辑
联想Thinkpad的F1~F12键功能与其他笔记本是相反的!
如果不按着Fn,在那几个功能键,实现的是属性设置的功能,比如直接按下F1键是静音,F2键是音量降低,F3是音量增加等等。如果按下Fn+F1键,则打开的是F1的功能,也就是系统帮助功能。
作者:AlbertWen
添加时间:2015-03-01 03:38:31
修改时间:2026-03-30 06:47:22
分类:
02.前端/Vue/Node.js
编辑
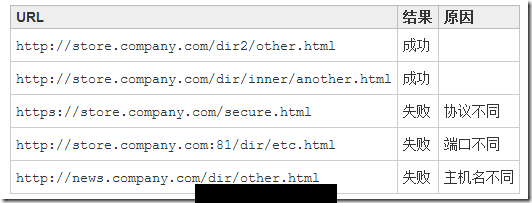
这里说的js跨域是指通过js在不同的域之间进行数据传输或通信,比如用ajax向一个不同的域请求数据,或者通过js获取页面中不同域的框架中(iframe)的数据。只要协议、域名、端口有任何一个不同,都被当作是不同的域。
下表给出了相对 http://store.company.com/dir/page.html 同源检测的结果:
作者:AlbertWen
添加时间:2017-10-26 14:24:15
修改时间:2026-04-01 09:48:09
分类:
06.Linux软件安装
编辑
几个Mac软件下载地址:
史蒂芬周的博客 [破解版软件 比较多]
精品MAC应用分享
爱情守望者
作者:AlbertWen
添加时间:2015-02-11 19:26:07
修改时间:2026-03-21 16:44:35
分类:
11.PHP基础
编辑
PHP里的__CLASS__这类东西是静态绑定的,如果不在子类里重载的话,那么继承父类方法所得到的依旧是父类的名称,而不是子类的名称,比如:
<?php
class A {
function __construct() {
echo __CLASS__;
}
static function name() {
echo __CLASS__;
}
}
class B extends A{
}
$objB = new B(); // 输出 A
B::name(); // 输出 A